AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTAMD Platform vs GIGABYTE: IO Power Overhead Gone
Starting off with the big change for toady’s review: the new production-grade GIGABYTE Milan compatible test platform.
In our original review of Milan, we had initially discovered that AMD’s newest generation chips had one large glass jaw: the platform’s extremely high idle package power behaviour exceeding 100W. This was a notable regression compared to what we saw on Rome, and we deemed it as a core cause as of why Milan was seeing some performance regressions in certain workloads compared to the predecessor Rome SKUs.
We had communicated our findings and worries to AMD prior to the review publishing, but never root-caused the issue, and never were able to confirm whether this was the intended behaviour of the new Milan chips or not. We theorized that it was a side-effect of the new sIOD which had the infinity fabric running at a higher frequency, which this generation runs in 1:1 mode with the memory controller clocks.
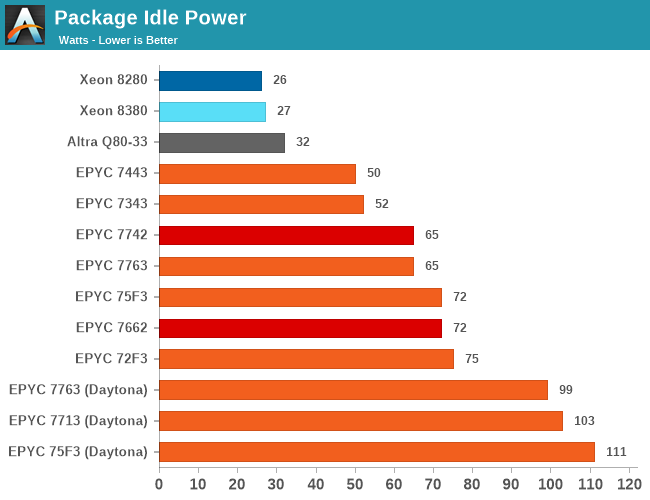
To our surprise, when setting up the new GIGABYTE system, we found out that this behaviour of extremely high idle power was not being exhibited on the new test platform.
Indeed, instead of the 100W idle figures as we had tested on the Daytona system, we’re now seeing figures that are pretty much in line with AMD’s Rome system, at around 65-72W. The biggest discrepancy was found in the 75F3 part, which now idles 39W less than on the Daytona system.
| Milan Power Efficiency | |||||||||||||
| SKU | EPYC 7763 (Milan) |
||||||||||||
| Motherboard/ Platform |
Daytona | GIGABYTE | |||||||||||
| TDP Setting | 280W |
||||||||||||
| Perf |
PKG (W) |
Core (W) |
Perf | PKG (W) |
Core (W) |
||||||||
| 500.perlbench_r | 281 | 274 | 166 | 317 | 282 | 195 | |||||||
| 502.gcc_r | 262 | 262 | 131 | 271 | 265 | 150 | |||||||
| 505.mcf_r | 155 | 252 | 115 | 158 | 252 | 132 | |||||||
| 520.omnetpp_r | 142 | 249 | 120 | 144 | 244 | 133 | |||||||
| 523.xalancbmk_r | 181 | 261 | 131 | 195 | 266 | 152 | |||||||
| 525.x264_r | 602 | 279 | 172 | 641 | 283 | 196 | |||||||
| 531.deepsjeng_r | 262 | 267 | 161 | 296 | 283 | 196 | |||||||
| 541.leela_r | 267 | 249 | 148 | 303 | 274 | 199 | |||||||
| 548.exchange2_r | 487 | 274 | 176 | 543 | 262 | 202 | |||||||
| 557.xz_r | 190 | 260 | 141 | 206 | 272 | 171 | |||||||
| SPECint2017 | 255 | 260 | 141 | 275 | 265 | 164 | |||||||
| kJ Total | 2029 | 1932 | |||||||||||
| Score / W | 0.980 | 1.037 | |||||||||||
| 503.bwaves_r | 354 | 226 | 90 | 362 | 218 | 99 | |||||||
| 507.cactuBSSN_r | 222 | 278 | 150 | 229 | 285 | 174 | |||||||
| 508.namd_r | 282 | 279 | 176 | 280 | 260 | 193 | |||||||
| 510.parest_r | 153 | 256 | 119 | 162 | 259 | 138 | |||||||
| 511.povray_r | 348 | 275 | 176 | 387 | 255 | 193 | |||||||
| 519.lbm_r | 39 | 219 | 84 | 40 | 210 | 92 | |||||||
| 526.blender_r | 372 | 276 | 165 | 396 | 282 | 188 | |||||||
| 527.cam4_r | 399 | 278 | 147 | 417 | 285 | 170 | |||||||
| 538.imagick_r | 446 | 278 | 178 | 471 | 268 | 200 | |||||||
| 544.nab_r | 259 | 278 | 175 | 275 | 282 | 198 | |||||||
| 549.fotonik3d_r | 110 | 220 | 86 | 113 | 215 | 95 | |||||||
| 554.roms_r | 88 | 243 | 106 | 89 | 241 | 119 | |||||||
| SPECfp2017 | 211 | 240 | 110 | 220 | 235 | 123 | |||||||
| kJ Total | 4980 | 4716 | |||||||||||
| Score / W | 0.879 | 0.9361 | |||||||||||
A more detailed power analysis of the EPYC 7763 during our SPEC2017 runs confirms the change in the power behaviour. Although the total average package power hasn’t changed much between the systems, in the integer suite now 5W higher at 265W vs 260W, and in the FP suite now 5W lower at 235W vs 240W, what more significantly changes is the core power allocation which is now much higher on the GIGABYTE system.
In core-bound workloads with little memory pressure, such as 541.leela_r, the core power of the EPYC 7763 went up from 148W to 199W, a +51W increase or +34%. Naturally because of this core power increase, there’s also a corresponding large performance increase of +13.3%.
The behaviour change doesn’t apply to every workload, memory-heavy workloads such as 519.lbm don’t see much of a change in power behaviour, and only showcase a small performance boost.
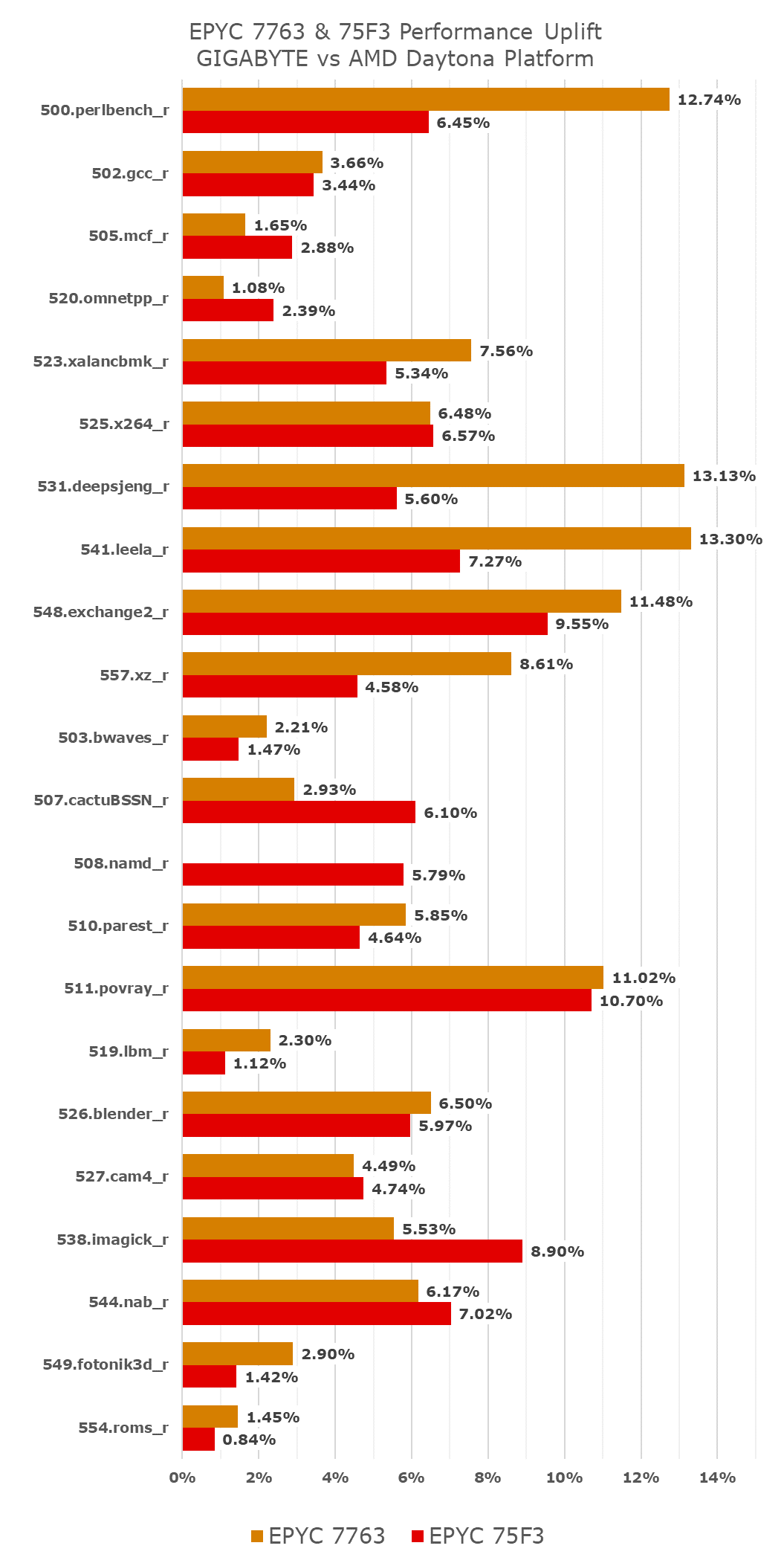
Reviewing the performance differences between the original Daytona system tested figures and the new GIGABYTE motherboard test-runs, we’re seeing some significant performance boosts across the board, with many 10-13% increases in compute bound and core-power bound workloads.
These figures are significant enough that they do change the overall verdict of those SKUs, and they also change the tone of our final review verdict on Milan, as evidently the one weakness the new generation had was actually not a design mishap, but actually was an issue with the Daytona system. It explains a lot of the more lacklustre performance increases of Milan vs Rome, and we’re happy that this was ultimately not an issue for production-grade platforms.
As a note, because we also have the 4-chiplet EPYC 7443 and EPYC 7343 SKUs in-house now, we also measured the platform idle power of those units, which came in at 50 and 52W. This is actually quite a bit below the 65-75W of the 8-chiplet 7763, 75F3 and 72F3 parts, which indicates that this power behaviour isn’t solely internal to the sIOD chiplet, but actually part of the sIOD and CCD interfaces, or as well the CCD L3 cache power.








58 Comments
View All Comments
eastcoast_pete - Friday, June 25, 2021 - link
Interesting CPUs. Regarding the 72F3, the part for highest per-core performance: Dating myself here, but I recall working with an Oracle DB that was licensed/billed on a per-core or per-thread basis (forgot which one it was). Is that still the case, and what other programs (still) use that licensing approach?And, just to add perspective: the annual payments for that Oracle license dwarfed the price of the CPU it ran on, so yes, such processors can have their place.
flgt - Friday, June 25, 2021 - link
More workstation than server, but companies like Ansys still require additional license packs to go beyond 4 cores with some of their tools, and they often come with hefty 5-figure price tags depending on the program and your organizations bargaining ability.RollingCamel - Friday, June 25, 2021 - link
It was refreshing to see Midas NFX running without core limitations.The core limitations archaic and doesn't represent the current development. Unless the license policies has evolved in the past years.
realbabilu - Monday, June 28, 2021 - link
Interesting to see The fea implementation with latest math kernel available like midas nfx bench in anandtech. Hopefullly anandteam got demos from midas korea for testing. Abaqus, msc nastran, inventor fea anything will do.However i dont think midas improved their math kernel, i had midas civil and gts licensed, but cant use all threads and all memory i had On my pc, like others fea dis.
mrvco - Friday, June 25, 2021 - link
Power unit pricing! LOL, the dreaded Oracle audit when they needed to find a way to make their quarterly numbers!?!?!eek2121 - Friday, June 25, 2021 - link
It blows my mind that people still use Oracle products.Urbanfox - Sunday, June 27, 2021 - link
For a lot of things there isn't a viable alternative. The hotel industry is a great example of this with Opera and Micros.phr3dly - Friday, June 25, 2021 - link
In the EDA world we pay per-process licensing. As with your scenario, the license cost dwarfs the CPU cost, particularly over the 3-year lifespan of a server. You might easily spend 50x the cost of the server on the licenses, depending on the number of cores. Trying to optimize core speed/core count/eventual server load against license cost is a fun optimization problem.So yeah, the CPU cost is irrelevant. I'm happy to pay an extra several thousand dollars for a moderate performance improvement.
eldakka - Saturday, June 26, 2021 - link
> Oracle DB that was licensed/billed on a per-core or per-thread basis (forgot which one it was). Is that still the case, and what other programs (still) use that licensing approach?Lots of Enterprise applications still use that approach, Oracle (not just DB), IBM products - WebSphere Application Server (all flavours, standalone, ND, Liberty, etc.), messaging products like WebSphere MQ, I believe SAP uses it, many RedHat 'middleware' products (e.g. JBOSS web server, EAS, etc.) use it as well.
In the enterprise space, it is basically the expected licensing model.
And the licensing cost per-core is usually 'generation' dependant. So you usually just can't upgrade from, say, a 20-core Xeon 6th-gen to a 20-core 8th gen and expect to pay the same.
The typical model is a 'PVU', Processor Value Unit (different companies may give it a different label - and value different processors differently, but it usually boils down to the same thing). Each platform-generation (as decided by the software vendor, i.e. Oracle, or IBM, etc.) has a certain PVU per core. E.g., (making up numbers here) a POWER8 (2014ish release) might have a PVU of 4000, and an Intel Haswell/Ivy Bridge - E5/7 v2/3 I think (2014/15ish)- might be given 3500. So if using an 8-core P8 LPAR that'd be 32000 PVU, while an 8 core VI on E7 v3 would be 28000. And P9 might be 7000 PVU, a Milan might be 6000 PVU, so for 8-cores it'd be 56000 or 48000 respectively. Then there will be a doller per PVU multiplier based on the software, so software bob could be x1 per year, so in the P9 case $56k/year license, whereas software fred mught be a x4 multiplier, so $224k/year. And yes, there can be instances where software being run on a single server (not even necessarily a beefy server) can be $millions/year licensing. If some piece of software is critical, but low CPU/memory requirements, such as an API-layer running on x86 hardware that allows midrange-based apps to interface directly to mainframe apps, they can charge millions for it even if its only using combined 8-cores across 4 2-core server instances (for HA) - though in this case, where they know it requires tiny resources, they'll switch to a per-instance rather than a per-core pricing model, and charge $500k per instance for example.
The per-core PVU can even change within a generation depending on specific CPU feature sets, e.g. the 2TB per-socket limited Xeon might be 5000 PVU, but the 4TB per-socket SKU of the same generation might be 6000 PVU, just because the vendor thinks "they need lots of memory, therefore they are working on big data sets, well, obviously, that's more money!" they want their tithe.
Oh, and nearly forgot to mention, the PVU can even change depending on whether the software vendor is tring to push their own hardware. IBM might give a 'PVU' discount if you run their IBM products on IBM Power hardware versus another vendors hardware, to try and push Power sales. So even though, in theory, a P9 might be more PVU than a Xeon, but since you are running IBM DB2 on the P9, they'll charge you less money for what is conceptually a higher PVU than on say a Xeon, to nudge you towards IBM hardware. Oracle has been known to do this with their aquired SPARC (Sun)-based hardware too.
eastcoast_pete - Saturday, June 26, 2021 - link
Thanks! I must say that I am glad I don't have to deal with that aspect of computing anymore. I also wonder if people have analyzed just how severely these pricing schemes have blunted or prevented advancements in hardware capabilities?